
MapReduce基础编程,Hadoop实现WordCount实例(打包上传到Linux服务器运行)
没有配置好环境的同学看我的传送门
Deepin(Ubuntu通用)安装Hadoop伪分布环境(集成Hbase、Hive、MySQL、Spark、Scala)
1、在Windows下下载Hadoop
bfsu这个镜像最快,清华的经常断
下载完成后解压
2、使用idea新建Java工程
新建一个普通的java项目就行,jdk最好用1.8,不然有可能会报错
首先在新建的项目文件夹里新建一个文件夹,存放要导入的jar包
将下载的Hadoop解压后share里面的这五个文件夹里的jar包全部粘贴到项目目录下新建的“引入的jar包”内
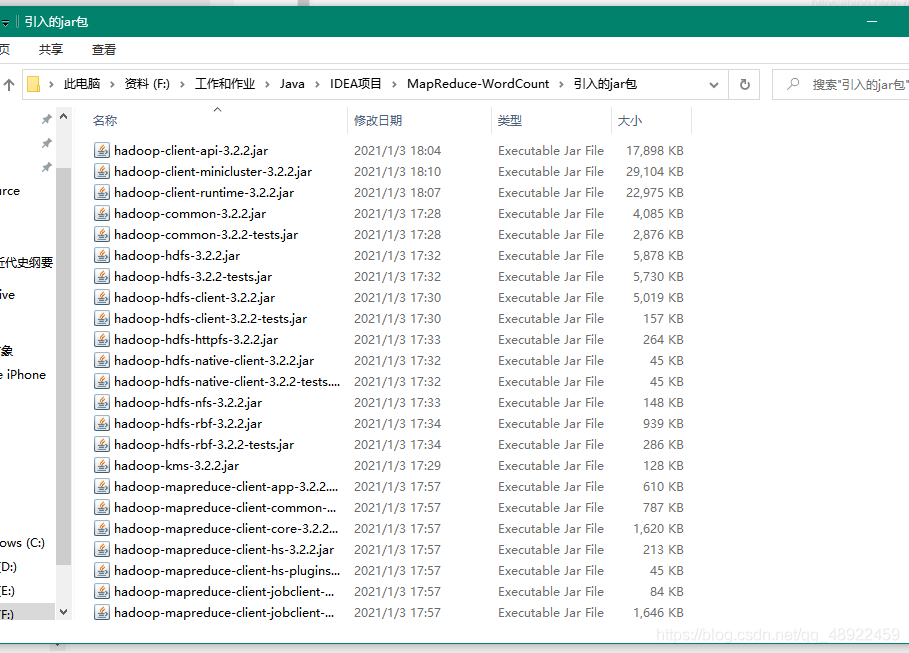
在 idea 中配置引入的 jar 包
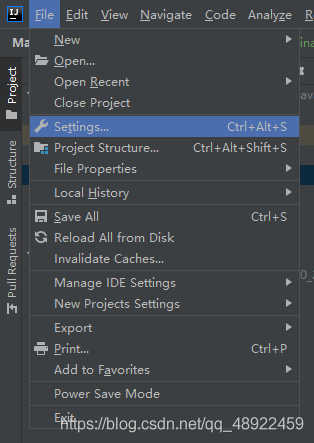
选择自己新建的存放 jar 包的文件夹
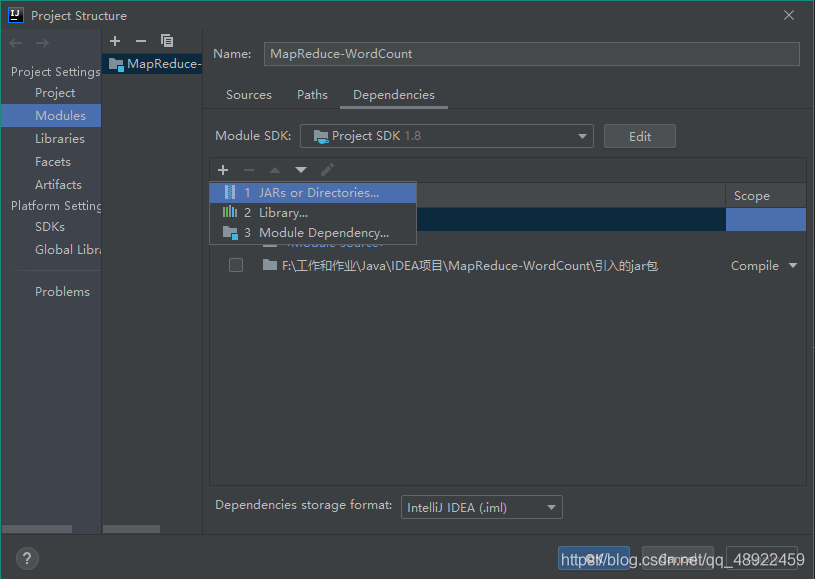
3、编写代码
新建 WordCount java 文件
代码如下
1 | import java.io.IOException; |
然后就可以运行了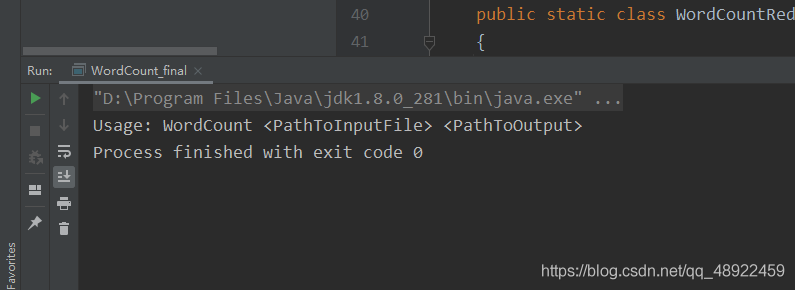
4、将编写的Java项目导出成jar包
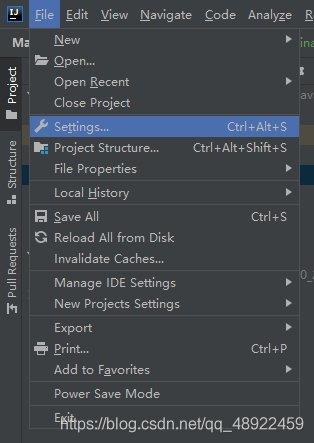
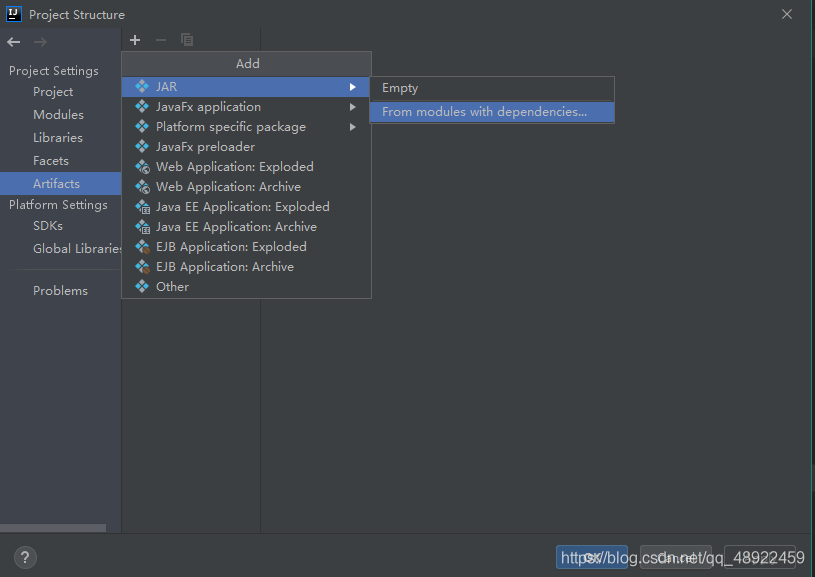
点击OK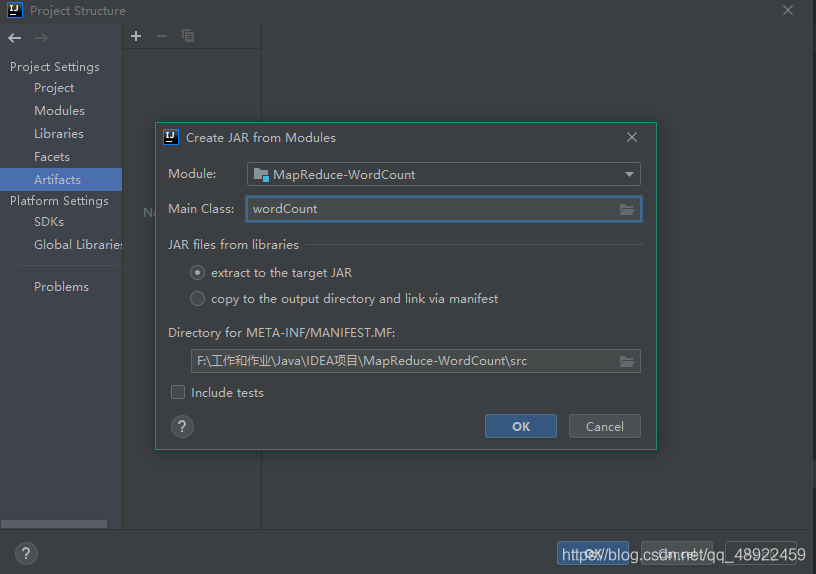
点击OK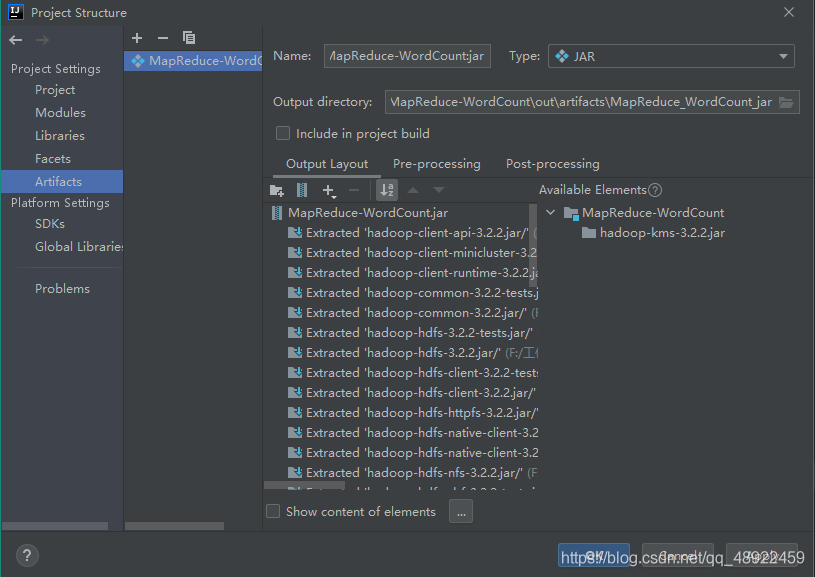
然后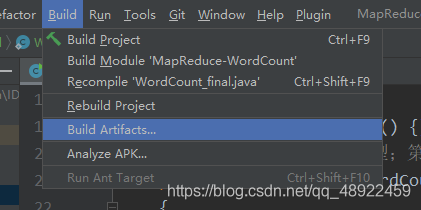
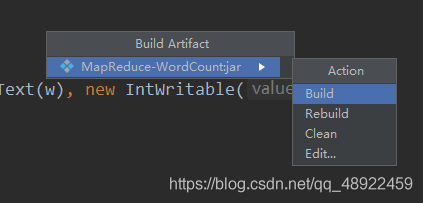
完成后就在项目目录下的 out 文件夹下的 artifacts 生成了 jar 包
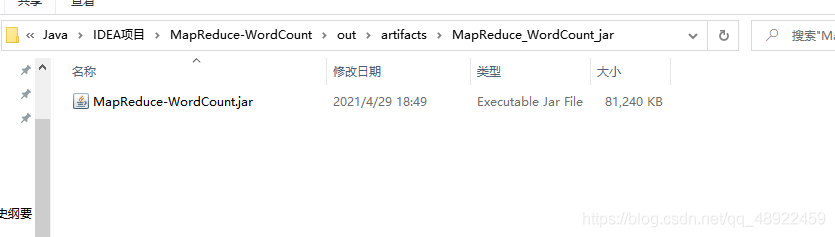
5、将jar包导入到Linux
进入到你的服务器的hadoop所在的文件夹,我的在 /usr/local/hadoop 你们的可能不一样
1 | cd /usr/local/hadoop |
在 hadoop 的 bin 文件夹下的 hadoop 文件夹创建文件夹 input
1 | ./bin/hadoop fs -mkdir /input |

把 jar 包复制到服务器
移动到创建的文件夹 input 里面
/home/xyj/classes/hadoop.jar 是jar包在我的服务器的位置, 这句话意思是把 jar 包移动到 /input 文件夹
1 | bin/hadoop fs -put /home/xyj/classes/hadoop.jar /input |
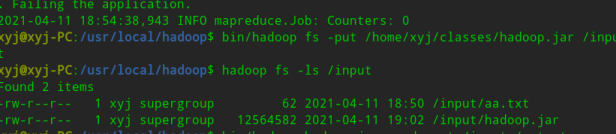
查看是否上传成功
1 | hadoop fs -ls /input |

输入 bin/hadoop MapReduce-WordCount.jar wordcount /input /output运行jar包
MapReduce-WordCount.jar为打包的jar包名,可能你们的不一样
即可获得运行结果
总结
没有总结
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 泡泡的博客!
 wechat
wechat alipay
alipay
相关推荐

2022-05-09
Debian(Linux) 安装Windows通用字体(可解决TimesNewRoman等字体的报错)
前言最近写了个小玩意儿,PDF转Word,体验很棒,图片和插画都能识别出来正确转换,可是部署到线上以后,转换会有Arial和TImesNewRoman字体的报错 原因就是Linux的字体和Windows的不太一样,毕竟PDF都是WIndows上面保存下来的。 一、直接操作123456sudo apt install ttf-mscorefonts-installer # 安装#这里刷新两遍缓存,保险sudo fc-cache -f -vsudo fc-cache#测试一下TimesNewRoman这个字体有没有安装成功fc-match Times 大功告成然后一定要重启报错的项目 总结完

2022-04-10
AWS Airport 搭建日志
前言仅供学习交流,为了我们大家好,不要在网络上传播本篇内容 ==注意,下面的服务器操作请务必使用root用户,或者每句命令前加 sudo== 一、安装谷歌BBR加速 TCP BBR是谷歌出品的TCP拥塞控制算法。BBR目的是要尽量跑满带宽,并且尽量不要有排队的情况。BBR可以起到单边加速TCP连接的效果。Google提交到Linux主线并发表在ACM queue期刊上的TCP-BBR拥塞控制算法。继承了Google“先在生产环境上部署,再开源和发论文”的研究传统。 TCP-BBR已经再YouTube服务器和Google跨数据中心的内部广域网(B4)上部署。由此可见出该算法的前途。TCP-BBR的目标就是最大化利用网络上瓶颈链路的带宽。一条网络链路就像一条水管,要想最大化利用这条水管,最好的办法就是给这跟水管灌满水。 BBR解决了两个问题:在有一定丢包率的网络链路上充分利用带宽。非常适合高延迟,高带宽的网络链路。降低网络链路上的buffer占用率,从而降低延迟。非常适合慢速接入网络的用户。Google 在 2016年9月份开源了他们的优化网...
2021-04-08
Deepin(Linux)安装Hadoop伪分布环境(集成Hbase、Hive、MySQL、Spark、Scala)
安装版本 jdk8、Hadoop3.2.2、Hbase2.4.17、Hive3.1.2、MySQL8.0.24、Spark3.1.1、Scala2.13.5(版本不对会报错,我下面均使用压缩包来安装对应版本) 下载所有环境 Hadoop3.2.2下载 bfsu这个镜像下载最快 Hbase2.4.17下载 选择bin.tar.gz Hive3.1.2下载选择bin.tar.gz Spark下载地址记得第2栏选择Hadoop版本,本教程是3.2 Scala2.13.5下载地址 进去官网后拉到最底部,选择第一个 MySQL下载地址 这里一定要选择这个Linux Generic下载前面这两个,64位和32位根据自己电脑情况来选 开启Deepin或Ubuntu(我用的是虚拟机) 我用的是Deepin20(Debian10 Buster库)好看吧, 还有“QQ2008” 安装Hadoop1、安装和配置ssh 首先在终端输入sudo apt update来更新一下apt的包列表(apt代表赋予管理员权限,建议每句命令都加上) 输入sudo apt-g...

2022-01-05
Linux 配置 MySQL 定时自动备份到另一台服务器
前言此方案可使一台服务器上的 MySQL 中的所有数据库每天 0 点自动转储为 .sql 文件,然后将文件同步到另一台服务器上,可以作为一个简单的数据容灾。 二、编写自动备份 sh 文件在数据库所在的服务器新建一个 sh 文件,放在哪里、怎样命名都随意(此处注意!!!不要使用 xftp 右键新建文件来编写 sh 文件,那样编码会出问题,比如新建的文件名后面会多出一个问号“?”,使用命令行vim或vi来新建) 1234mkdir mysqlAutoBackupTo24cd mysqlAutoBackupTo24mkdir backupvim AutoBackup.sh 我建立的文件夹是这样的 AutoBackup.sh 里面的内容 1234567891011121314151617181920#下面生成的sql在本服务器存放的文件夹,就是我上面建立的BACKUP=/data/mysqlAutoBackupTo24/backup#当前时间,用来命名sql文件DATETIME=$(date +%Y-%m-%d)echo "===备份开始==="echo &q...

2021-12-24
Linux使用Docker安装Nacos并配置MySQL数据源,将Springboot的配置文件部署到Nacos
前言 为什么要把配置文件放到 Nacos 上1、 采用本地配置,不方便查看当前项目配置,也不方便修改(要重新打包重启),在 Nacos 上可以方便地查看和修改2、易引发生产事故/方便开发测试:比如在发布的时候,容易将测试环境的配置带到生产上,引发生产事故,而项目的启动脚本可以指定 Nacos 上面的配置文件,从而使测试配置文件失效,所以开发的时候无需把精力放在修改配置文件上 一、Docker中安装配置Nacos当然如果不安装在 Docker 里也行,不安装在 Docker 把在 Nacos 的官网下载文件,直接解压就行,跳过 docker pull 和 run 的过程就可以了,然后你要把 nacos 注册为服务,开机启动,然后其他步骤都一样,总之不安装在 Docker 有点麻烦的。 安装Docker所有 Linux 系统通用安装命令 1curl -sSL https://get.daocloud.io/docker | sh 拉取Nacos镜像注意,一定要拉取 1.4.1 的版本,因为下面我给的配置文件是 1.4.1 的,其他版本都会启动失败,Nacos 就是这么...

2021-12-20
Springboot物理地址映射和Nginx静态资源代理实现前端上传并访问服务器图片
前言为什么要配置物理地址映射:因为前端的 <img :src="">或者 :style="background-img(url)"这些,如果要给这些标签动态赋值,从后端传来的路径必须是 url 形式,也就是说带冒号的动态src或者url不支持绝对路径的物理地址。 所以要配置物理地址映射把图片的的物理地址映射为 url 地址传给前端。比如 ==D:/aa.png== 前端 ==:src== 无法识别,映射为 ==http://localhost/aa.png== 就可以识别了。 为什么要配置静态资源代理:理由和上面一样,只是这个配置是项目部署到服务器上必须要添加的。也就是说项目在本地跑,上传和访问本地的图片,只需要配置Springboot的物理地址映射就可以了。 本篇文章没有介绍如何从前端上传图片并使用后端处理后讲 base64 转化为 url 存入数据库,我的另一篇有详细讲。传送门:Vue+Springboot上传图片将...
评论