安装版本
jdk8、Hadoop3.2.2、Hbase2.4.17、Hive3.1.2、MySQL8.0.24、Spark3.1.1、Scala2.13.5
下载所有环境
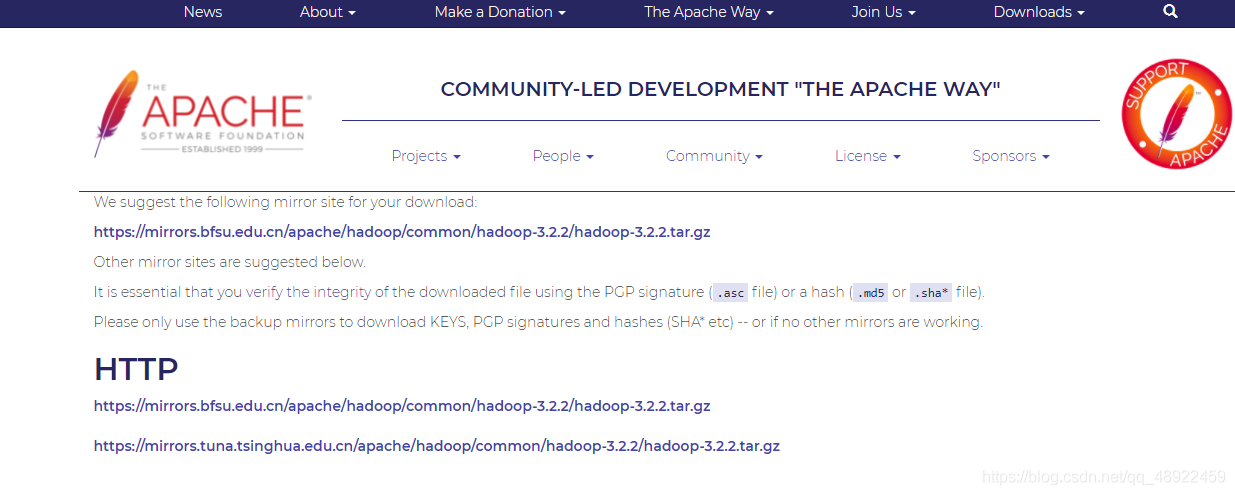
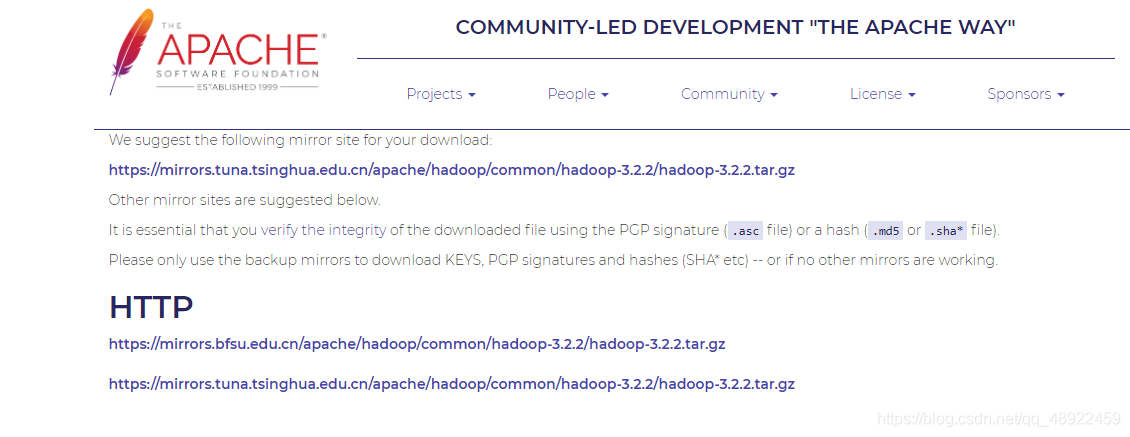
Hadoop3.2.2下载 bfsu这个镜像下载最快
Hbase2.4.17下载 选择bin.tar.gz
Hive3.1.2下载 选择bin.tar.gz
Spark下载地址 记得第2栏选择Hadoop版本,本教程是3.2
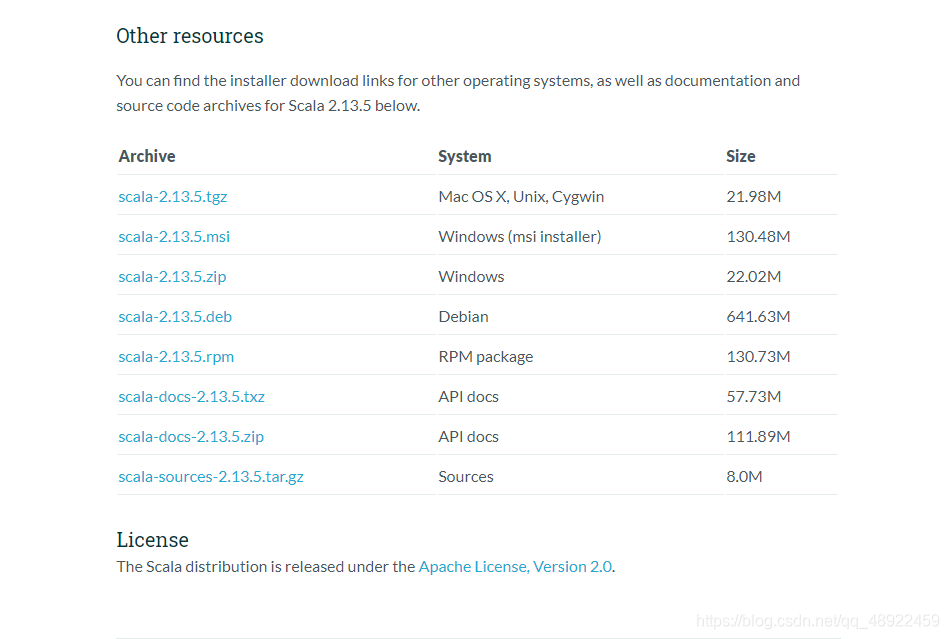
Scala2.13.5下载地址 进去官网后拉到最底部,选择第一个
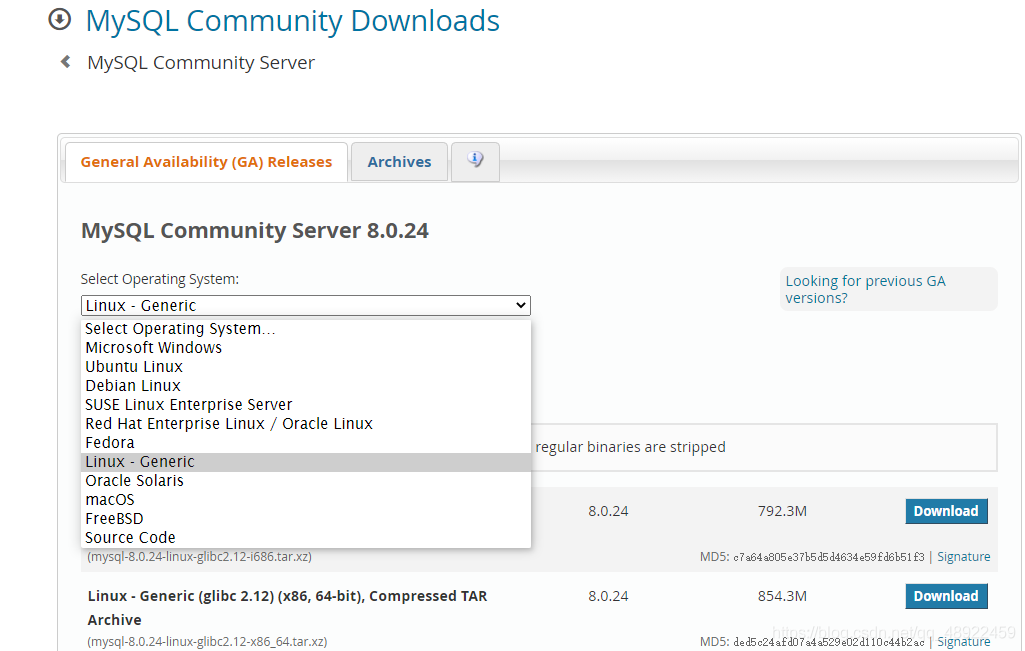
MySQL下载地址
这里一定要选择这个Linux Generic
开启Deepin或Ubuntu(我用的是虚拟机)
我用的是Deepin20(Debian10 Buster库)好看吧, 还有“QQ2008”
安装Hadoop 1、安装和配置ssh
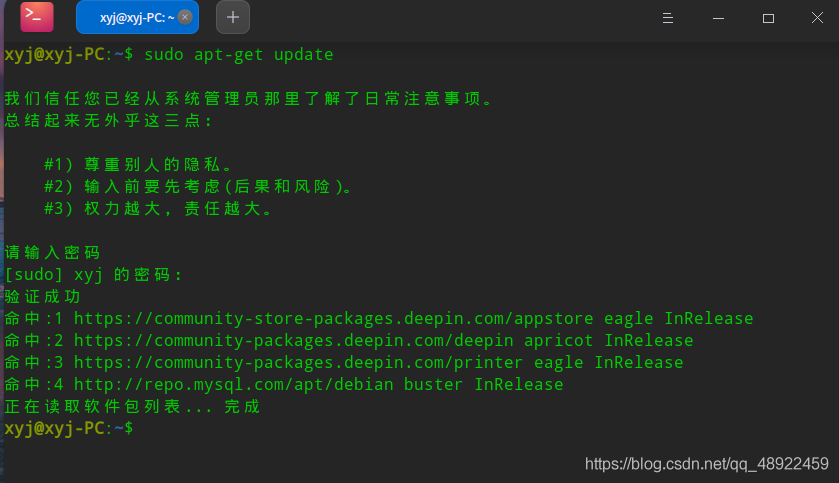
首先在终端输入sudo apt update来更新一下apt的包列表(apt代表赋予管理员权限,建议每句命令都加上)
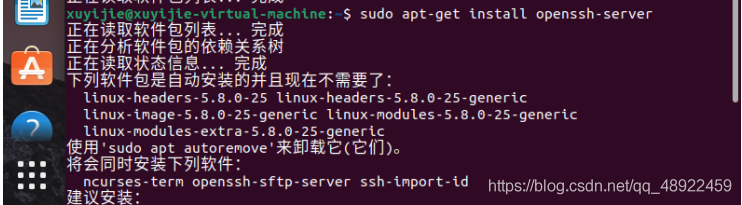
输入sudo apt-get install openssh-server回车,再输入sudo apt-get install openssh-client回车(Deepin可能已经预装了ssh,不过再输入一下确认一下也没什么)
Deepin已经安装过是如下界面
配置ssh无密码自动登录(很重要)
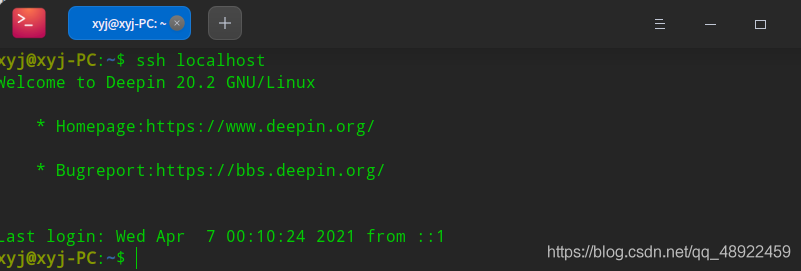
1 ssh localhost #登陆SSH,第一次登陆输入yes
1 exit #退出登录的ssh localhost
1 cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
输入完ssh-keygen -t rsa语句后,需要连续敲击三次回车
1 $ cat ./id_rsa.pub >> ./authorized_keys
2、安装和配置Java(一定要安装Java8版本,不然Hive、Spark和Scala会报错)
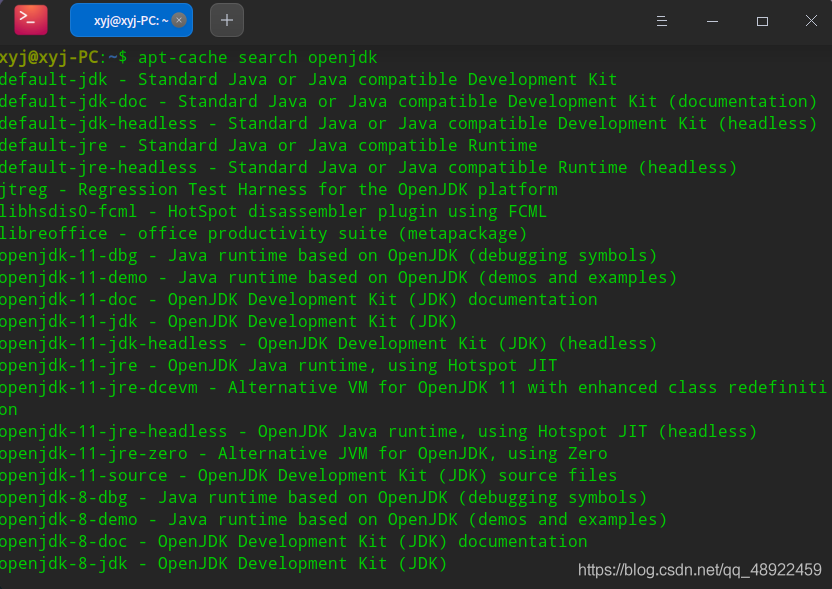
输入apt-cache search openjdk,这是查看可以安装的Java版本有哪些,查询结果显示如下,我们可以看到,又openjdk-8-jdk
接着,我们输入下面命令回车,等待下载就安装成功了
1 $ sudo apt-get install openjdk-8-jdk
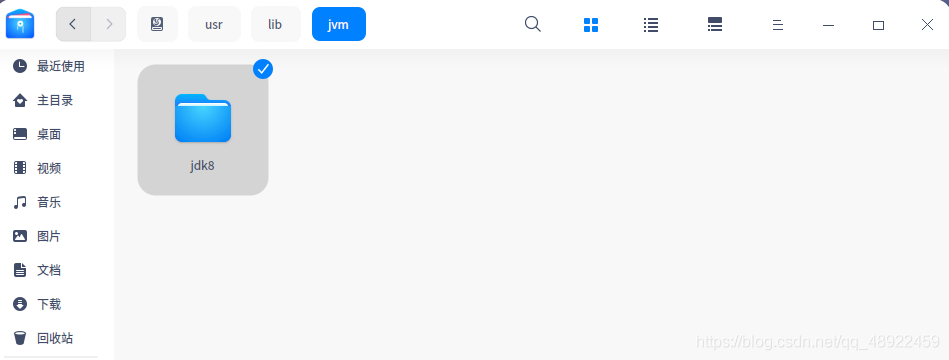
无论是Deepin还是Ubuntu,apt安装的Java都存在系统盘的usr/lib/jvm里
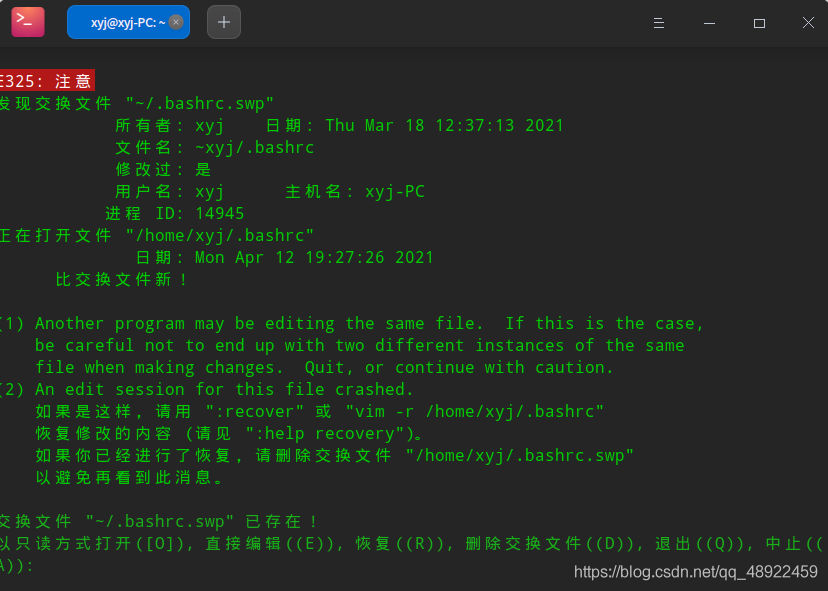
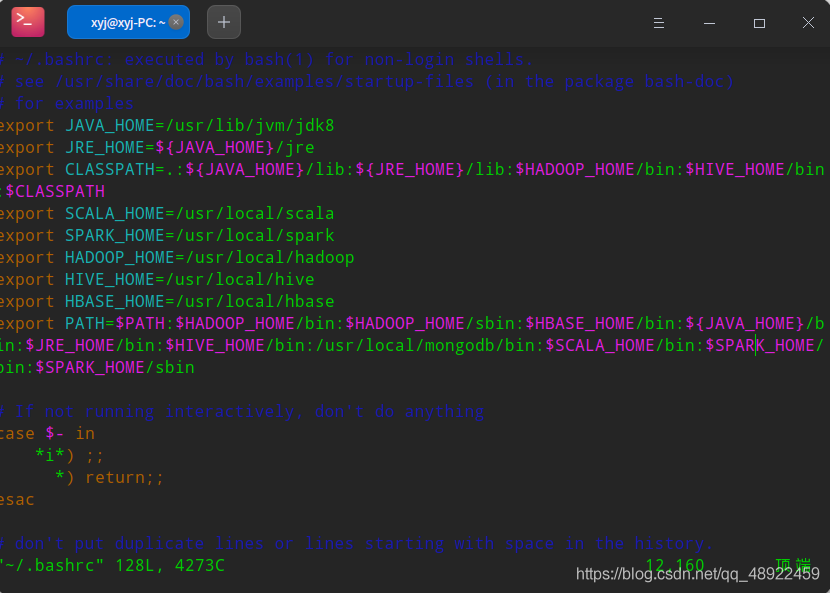
最后配置Java的环境变量vim ~/.bashrc,会进入一个文档,也许会出现这个页面,按一下键盘上的E就能进入文档了
进入文档后是这样的
我这边配置了本教程所有的环境变量,大家之间粘贴进去,后面就不用再配置了
注意!!!vim的操作和普通文本编辑器不同!!!
1 2 3 4 5 6 7 8 9 export JAVA_HOME=/usr/lib/jvm/jdk8export JRE_HOME=${JAVA_HOME} /jreexport CLASSPATH=.:${JAVA_HOME} /lib:${JRE_HOME} /lib:${HADOOP_HOME} /bin:$HIVE_HOME /bin:$CALSSPATH export SCALA_HOME=/usr/local/scalaexport SPARK_HOME=/usr/local/sparkexport HADOOP_HOME=/usr/local/hadoopexport HIVE_HOME=/usr/local/hiveexport HBASE_HOME=/usr/local/hbaseexport PATH=$PATH :$HADOOP_HOME /bin:$HADOOP_HOME /sbin:$HBASE_HOME /bin:${JAVA_HOME} /bin:$JRE_HOME /bin:$HIVE_HOME /bin:$SCALA_HOME /bin:$SPARK_HOME /bin:$SPARK_HOME /sbin
然后输入source ~/.bashrc,这个意思是使配置的环境变量立即生效
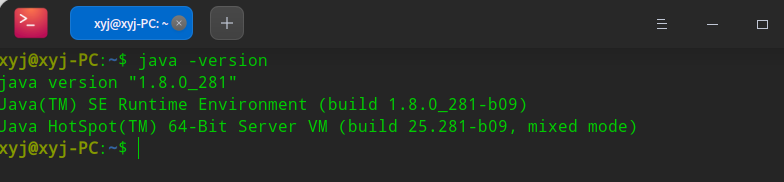
检查Java版本,安装并配置成功
3、安装Hadoop
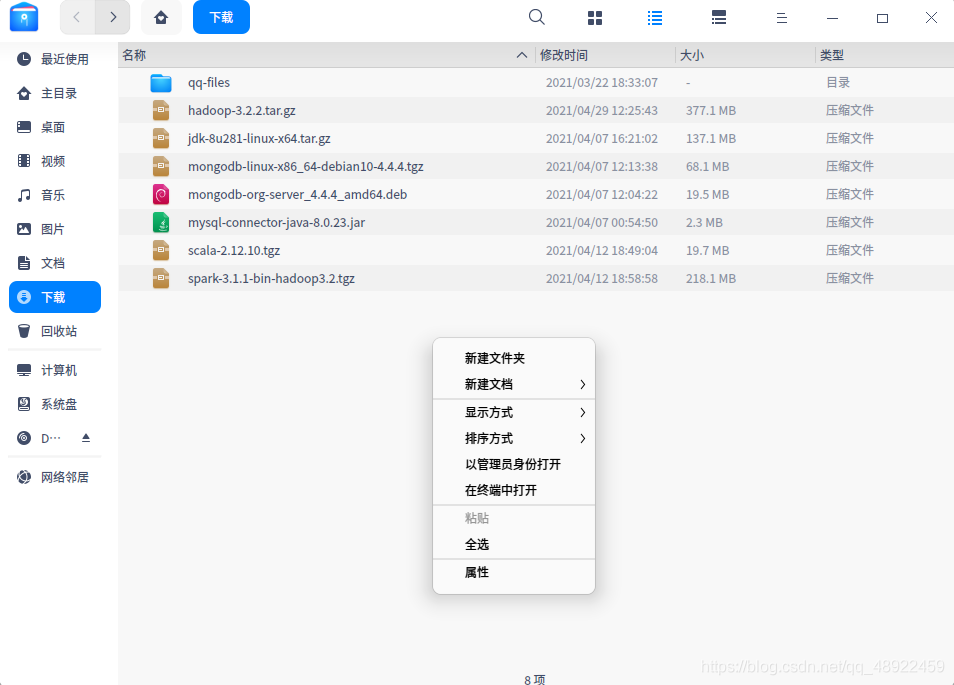
我们把下载好的Hadoop安装包放在“下载”文件夹里,Deepin下载的默认路径就是这个
在这个目录下右键选择“在终端中打开”
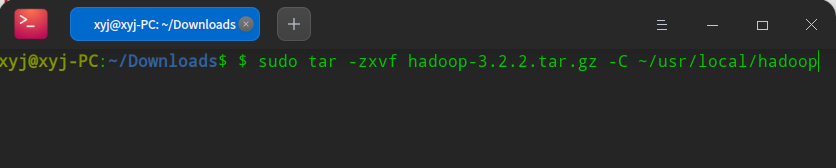
在打开的终端中输入下方命令,将下载的Hadoop压缩包解压到usr/local/hadoop-3.2.2文件夹下,hadoop-3.2.2.tar.gz是下载的文件名
1 sudo tar -zxvf hadoop-3.2.2.tar.gz -C /usr/local
然后将hadoop-3.2.2重命名为hadoop,依次执行下列命令
1 sudo mv ./hadoop-3.2.2 ./hadoop
查看文件夹,已经命名为hadoop
你们的hadoop文件夹上可能会带有一个黄色的锁🔒,这就还需要赋予hadoop文件夹权限,避免以后出现问题,接着执行下列命令,🔒就消失了,以后安装Hbase、Hive等,也是执行下列命令赋予权限,把文件夹名修改一下就行(如果不是图形界面你不知道是不是带锁也执行以下下面的命令,防止后面因为权限问题报错)
1 $ sudo chmod 777 -R hadoop
伪分布需要配置三个文件
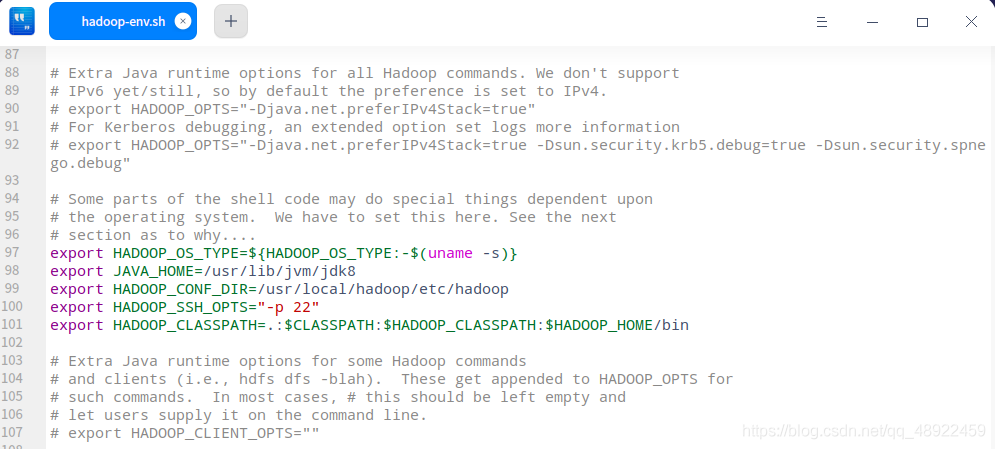
1、/hadoop/etc/hadoop路径下的hadoop-env.sh,右键打开方式选文本编辑器,添加下面代码进去
1 2 3 4 5 export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)} export JAVA_HOME=/usr/lib/jvm/jdk8export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopexport HADOOP_SSH_OPTS="-p 22" export HADOOP_CLASSPATH=.:$CLASSPATH :$HADOOP_CLASSPATH :$HADOOP_HOME /bin
2、/hadoop/etc/hadoop路径下的core-site.xml,添加下面代码进去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 <configuration > <property > <name > fs.default.name</name > <value > hdfs://localhost:9000</value > <description > HDFS的URI,文件系统://namenode标识:端口号</description > </property > <property > <name > hadoop.tmp.dir</name > <value > file:/usr/local/hadoop/tmp</value > <description > namenode上本地的hadoop临时文件夹</description > </property > <property > <name > dfs.permissions.enabled</name > <value > false</value > </property > <property > <name > hadoop.proxyuser.root.hosts</name > <value > *</value > </property > <property > <name > hadoop.proxyuser.root.groups</name > <value > *</value > </property > </configuration >
3、/hadoop/etc/hadoop路径下的hdfs-site.xml,添加下面代码进去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <configuration > <property > <name > dfs.namenode.name.dir</name > <value > file:/usr/local/hadoop/tmp/dfs/name</value > <description > namenode上存储hdfs名字空间元数据 </description > </property > <property > <name > dfs.datanode.data.dir</name > <value > file:/usr/local/hadoop/tmp/dfs/data</value > <description > datanode上数据块的物理存储位置</description > </property > <property > <name > dfs.checkpoint.dir</name > <value > file:/usr/local/hadoop/tmp/dfs/snn</value > <description > secondary namenode 的位置</description > </property > <property > <name > dfs.checkpoint.edits.dir</name > <value > file:/usr/local/hadoop/tmp/dfs/snn</value > <description > secondary namenode 的位置</description > </property > <property > <name > dfs.replication</name > <value > 1</value > <description > 副本个数,配置默认是3,应小于datanode机器数量</description > </property > </configuration >
Hadoop 的运行方式是由配置文件决定的,因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。此外,伪分布式虽然只需要配置 fs.defaultFS 和 dfs.replication 就可以运行(参考官方教程),不过若没有配置 hadoop.tmp.dir 参数,则默认使用的临时目录为 /tmp/hadoo-hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行 format 才行。所以我们进行了设置,同时也指定 dfs.namenode.name.dir 和 dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
配置完之后,执行根节点的格式化,在hadoop文件夹下右键,“在终端中打开”
输入bin/hdfs namenode -format
格式化根节点只在第一次配置完之后执行一次,切勿多次手动格式化,如果多次手动格式化导致DataNode或NameNode无法启动,请关闭Hadoop服务,删除hadoop文件夹下的这三个文件夹后,重新格式化根节点
4、启动Hadoop
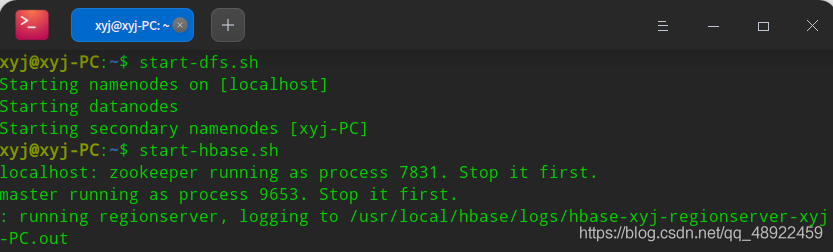
我们已经配置好环境变量,所以可以在终端中直接输入start-dfs.sh来启动Hadoop的服务
注意!!!!今后启动不再使用start-dfs.sh命令,因为这个命令没有启动所有的Hadoop服务,以后做项目或者配置其他环境会报错,我们这里只是测试hadoop是否安装成功才用这个命令,记住,所有东西都安装配置完以后启动Hadoop使用start-all.sh这个命令
打开浏览器,输入localhost:9870(Hadoop3的默认端口)
关闭Hadoop服务的命令是stop-dfs.sh
如果启动出现如下报错ERROR: Attempting to operate on hdfs namenode as rootERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.hadoop/sbin下面的start-dfs.sh和stop-dfs.sh,添加内容
1 2 3 4 5 6 HDFS_ZKFC_USER=root HDFS_JOURNALNODE_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=root
修改start-yarn.sh和stop-yarn.sh,添加内容
1 2 3 HDFS_DATANODE_SECURE_USER=root YARN_NODEMANAGER_USER=root YARN_RESOURCEMANAGER_USER=root
安装Hbase 1、解压Hbase
参考解压hadoop进行解压
本教程安装的所有的环境都解压在/usr/local里,后面不在赘述解压过程
2、配置Hbase伪分布环境
将下面代码复制到Hbase文件夹里的conf文件夹里的hbase-site.xml文件中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 <configuration > <property > <name > hbase.rootdir</name > <value > hdfs://localhost:9000/hbase</value > </property > <property > <name > hbase.cluster.distributed</name > <value > true</value > </property > <property > <name > hbase.zookeeper.quorum</name > <value > localhost</value > </property > <property > <name > dfs.replication</name > <value > 1</value > </property > <property > <name > hbase.unsafe.stream.capability.enforce</name > <value > false</value > </property > <property > <name > hbase.zookeeper.property.clientPort</name > <value > 2182</value > </property > <property > <name > hbase.master.info.port</name > <value > 60010</value > </property > </configuration >
将下面代码复制到Hbase文件夹里的conf文件夹里的hbase-env.sh文件中
1 2 3 4 export JAVA_HOME=/usr/lib/jvm/jdk8export HBASE_MANAGES_ZK=true export HBASE_CLASSPATH=/usr/local/hbase/confexport HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
然后就可以start-hbase.sh启动Hbase了,注意,启动Hbase之前先启动Hadoop,关闭Hbase的命令是stop-hbase.sh
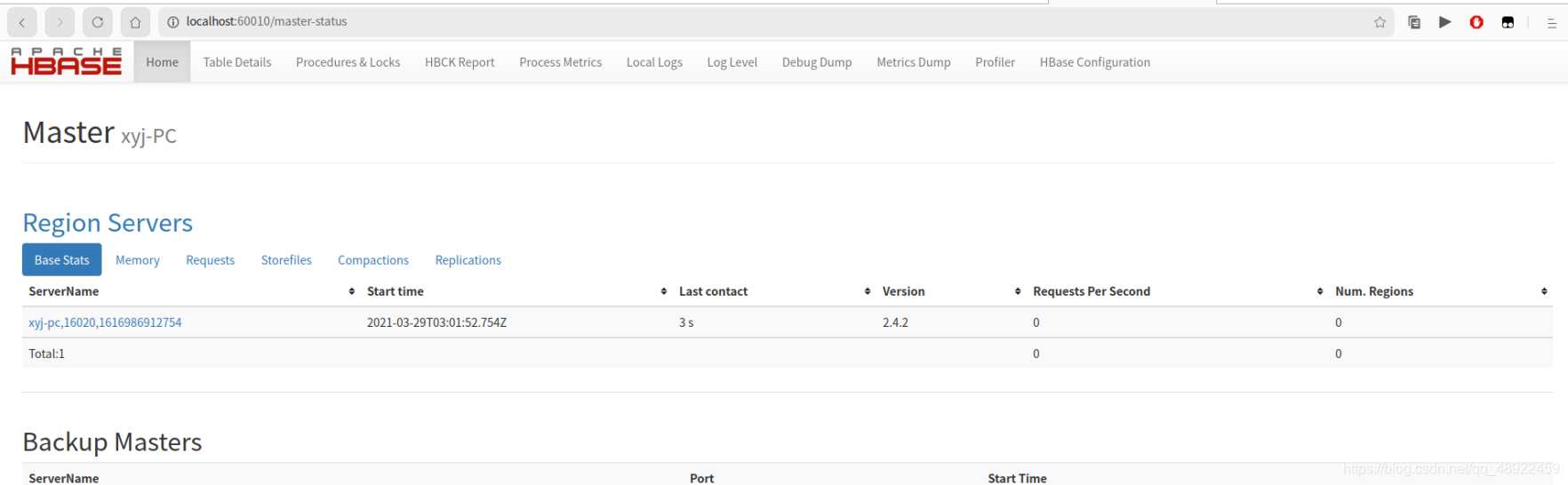
可以localhost:60010访问Hbase页面
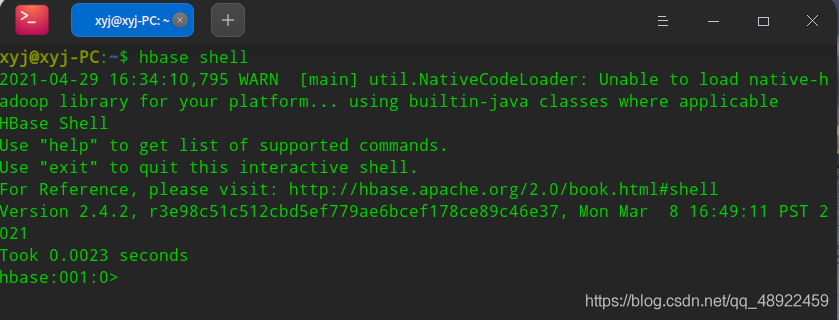
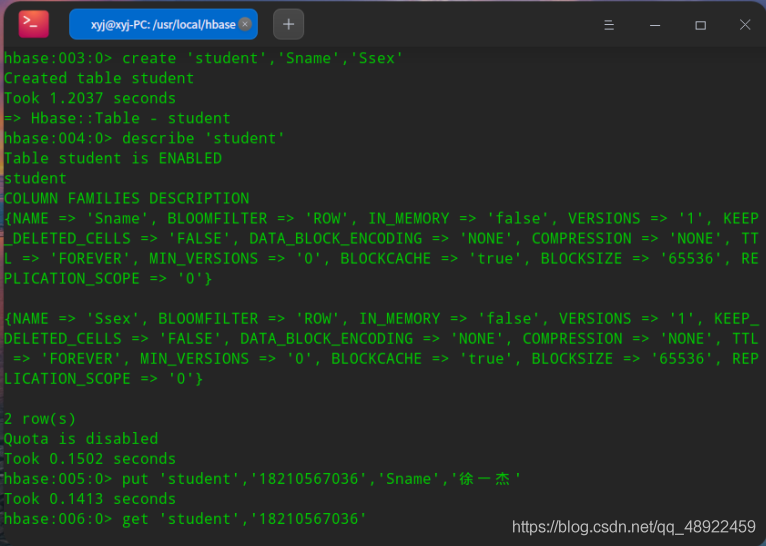
3、hbase shell的基本操作
输入hbase shell可以打开hbase shell
退出shell输入exit回车
安装Hive 1、安装Hive
解压过程不赘述,请看安装Haoop板块介绍的方法
修改Hive/conf文件夹下的hive-site.xml,如果没有就在该文件夹下右键,“在终端中打开”,使用下面命令新建一个hive-site.xml
1 sudo gedit hive-site.xml
或者直接右键,新建文本文档,后缀修改为xml
在hive-site.xml中这样写,此配置为MySQL8.0.24的配置,如果版本低于8,则不是这样配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 <?xml version="1.0" encoding="UTF-8" standalone="no" ?> <?xml-stylesheet type="text/xsl" href="configuration.xsl" ?> <configuration > <property > <name > javax.jdo.option.ConnectionURL</name > <value > jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value > <description > JDBC connect string for a JDBC metastore</description > </property > <property > <name > javax.jdo.option.ConnectionDriverName</name > <value > com.mysql.cj.jdbc.Driver</value > <description > Driver class name for a JDBC metastore</description > </property > <property > <name > javax.jdo.option.ConnectionUserName</name > <value > hive</value > <description > username to use against metastore database</description > </property > <property > <name > javax.jdo.option.ConnectionPassword</name > <value > hive</value > <description > password to use against metastore database</description > </property > <property > <name > hive.metastore.warehouse.dir</name > <value > /usr/local/hive/warehouse</value > </property > <property > <name > hive.exec.scratchdir</name > <value > /usr/local/hive/tmp</value > </property > <property > <name > hive.querylog.location</name > <value > /usr/local/hive/log</value > </property > <property > <name > hive.metastore.uris</name > <value > thrift://linux100:9083</value > </property > <property > <name > hive.server2.thrift.port</name > <value > 10000</value > </property > <property > <name > hive.server2.thrift.bind.host</name > <value > 0.0.0.0</value > </property > <property > <name > hive.server2.webui.host</name > <value > 0.0.0.0</value > </property > <property > <name > hive.server2.webui.port</name > <value > 10002</value > </property > <property > <name > hive.server2.long.polling.timeout</name > <value > 5000</value > </property > <property > <name > hive.server2.enable.doAs</name > <value > true</value > </property > <property > <name > datanucleus.autoCreateSchema</name > <value > false</value > </property > <property > <name > datanucleus.fixedDatastore</name > <value > true</value > </property > <property > <name > hive.execution.engine</name > <value > mr</value > </property > <property > <name > hive.cli.print.header</name > <value > true</value > </property > <property > <name > hive.cli.print.current.db</name > <value > true</value > </property > </configuration >
修改hive/conf文件夹下的hive-env.sh,添加下面语句
1 2 3 export HADOOP_HOME=/usr/local/hadoop/export HIVE_CONF_DIR=/usr/local/hive/conf/export HIVE_AUX_JARS_PATH=/usr/local/hive/lib
2、安装MySQL
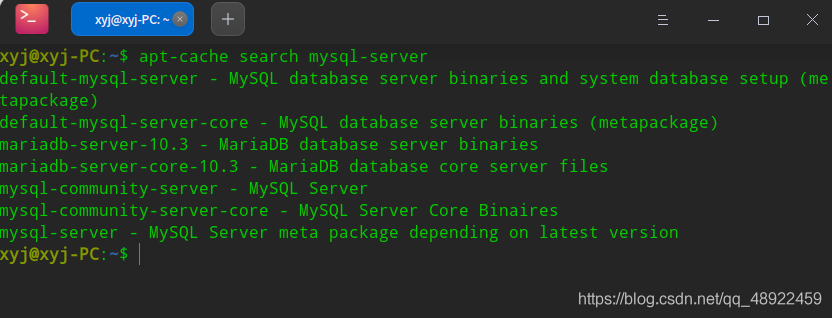
MySQL可以使用apt安装,Deepin默认的MySQL就是最新版,Ubuntu我不知道是不是,可以使用下面命令看一下版本
然后使用下面命令安装MySQL
1 sudo apt-get install mysql-server
安装完成后查看MySQL版本
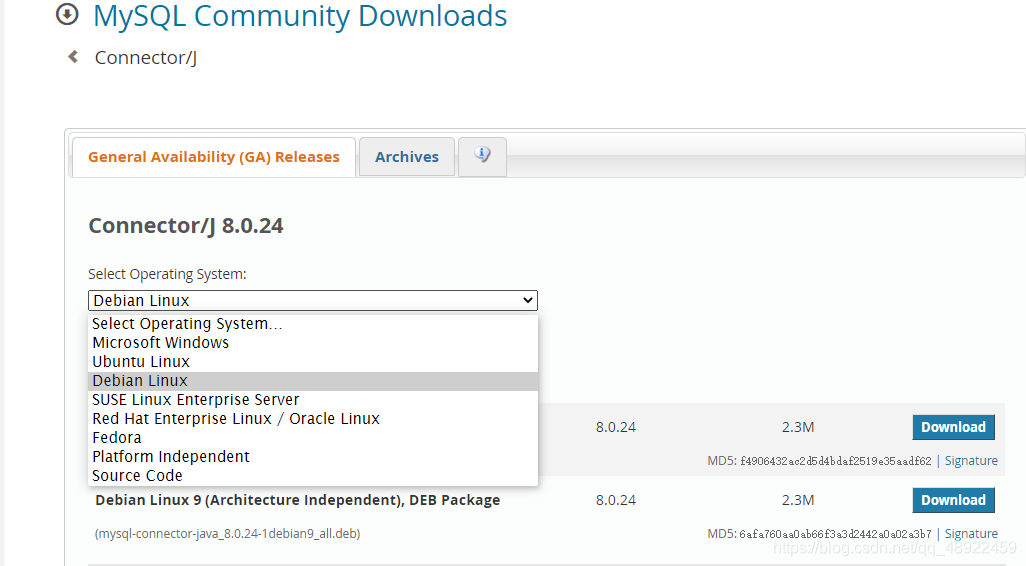
接下来还要安装一个mysql-connector-java下载地址
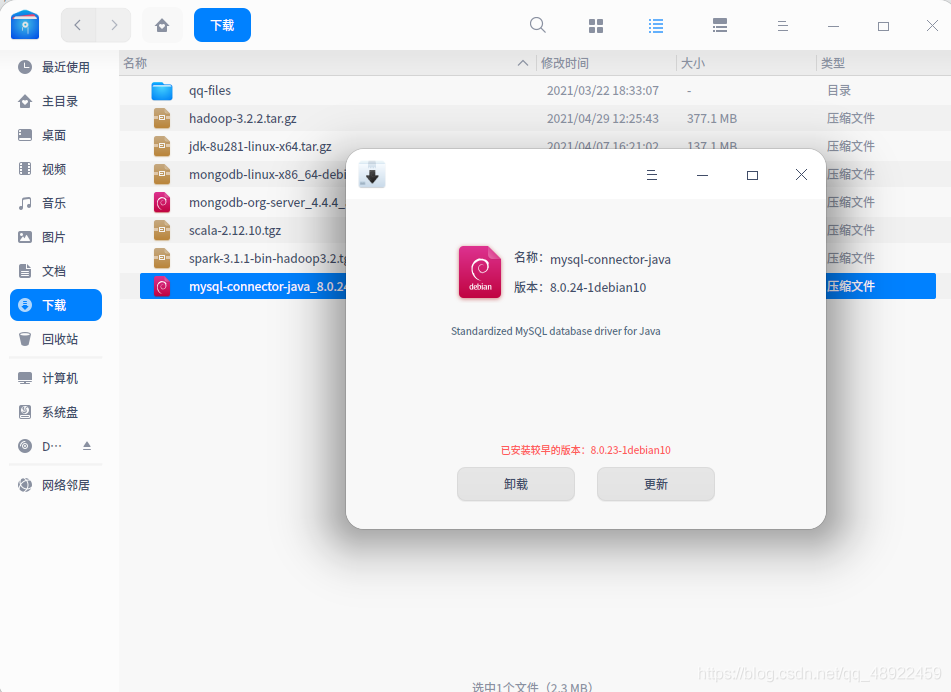
下载完成后,文件是deb格式,直接双击点击安装就行了,我的因为安装过了,只有更新可以点
在终端输入以下命令启动MySQL服务
1 sudo systemctl start mysql
执行下面命令初始化MySQL,设置密码等操作
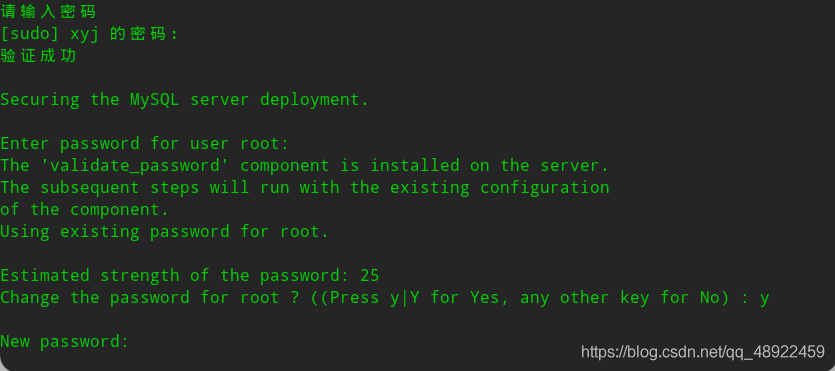
1 sudo mysql_secure_installation
为MySQL设置密码(mysql8版本一定要设置,而且密码不能为空,不然后面报错)
然后下面会让你输入很多Y/N,全部输入Y回车
完成所有设置后,以root用户登录MySQL。 在终端中,键入以下命令:mysql -u root -p,输入 root用户的密码,然后按Enter ,登陆进MySQL
新建hive数据库,别忘了加分号
然后依次输入下面语句,意思是将所有数据库的所有表的所有权限赋给hive用户,后面的hive是配置hive-site.xml中配置的连接密码
1 2 CREATE USER 'hive' @'localhost' IDENTIFIED BY 'hive' ;GRANT ALL ON * .* TO 'hive' @'localhost' ;
然后输入下面语句
1 flush privileges; #刷新mysql系统权限关系表
再新建一个数据库叫hive
3、启动Hive
启动Hive之前,先运行start-all.sh启动Hadoop集群,然后输入hive启动
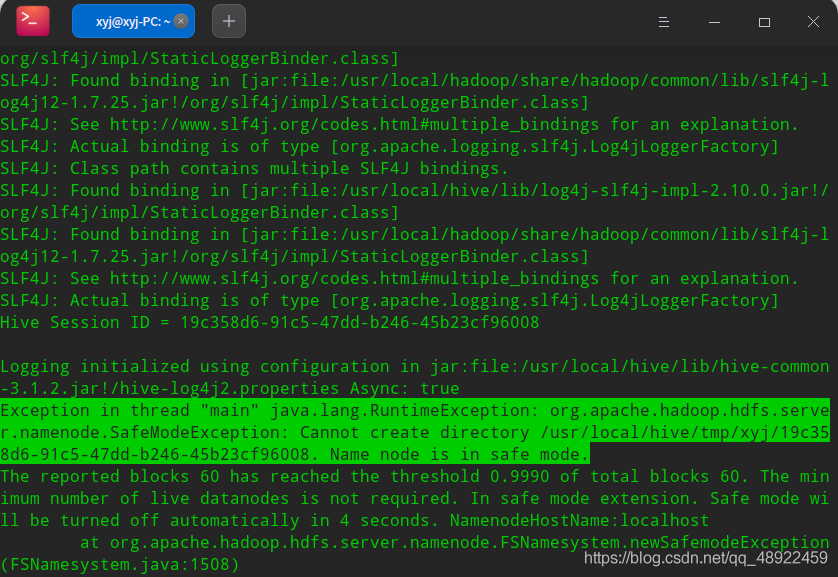
如果输入hive以后出现下面报错
则输入hdfs dfsadmin -safemode leave关闭安全模式,再运行hive即可
启动成功,输入exit;可退出hive shell
安装Spark 1、安装Scala语言支持
解压不再赘述,请看安装Hadoop板块介绍的方法,安装好查看版本
2、安装Spark
配置spark/conf文件夹下的spark-env.sh
在最后一行下面添加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 export JAVA_HOME=/usr/lib/jvm/jdk8export HADOOP_HOME=/usr/local/hadoopexport HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoopexport SCALA_HOME=/usr/local/scalaexport SPARK_HOME=/usr/local/sparkexport SPARK_MASTER_IP=127.0.0.1export SPARK_MASTER_PORT=7077export SPARK_MASTER_WEBUI_PORT=8099export SPARK_WORKER_CORES=3export SPARK_WORKER_INSTANCES=1export SPARK_WORKER_MEMORY=5Gexport SPARK_WORKER_WEBUI_PORT=8081export SPARK_EXECUTOR_CORES=1export SPARK_EXECUTOR_MEMORY=1Gexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH} :$HADOOP_HOME /lib/native
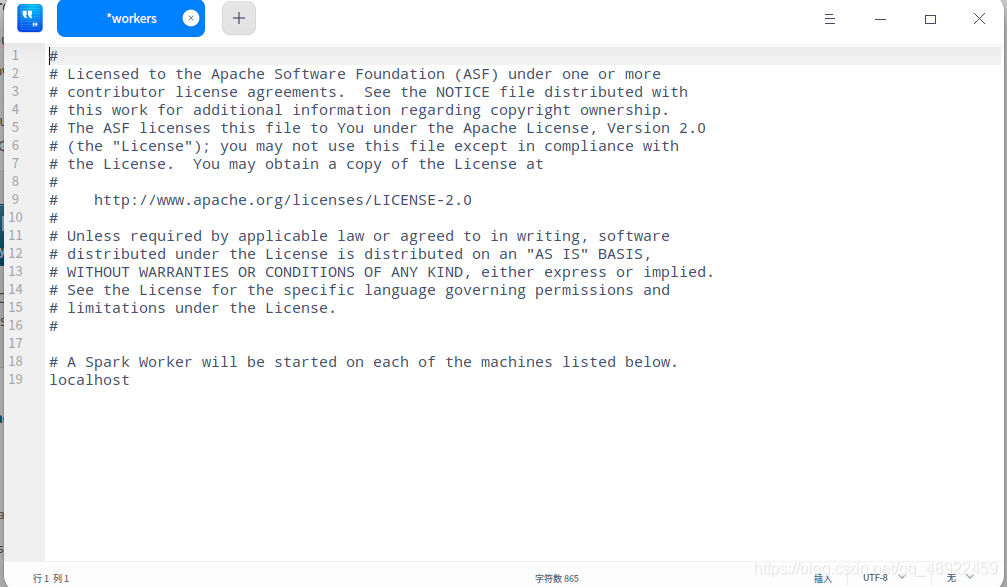
配置spark/conf文件夹下的worker,就在最后一行下面加上一个localhost即可(Spark基于hadoop3.2版本的配置文件从slaves变成了worker,旧版本为slaves)
3、启动Spark
启动Spark之前,同样要先保证Hadoop集群已经启动
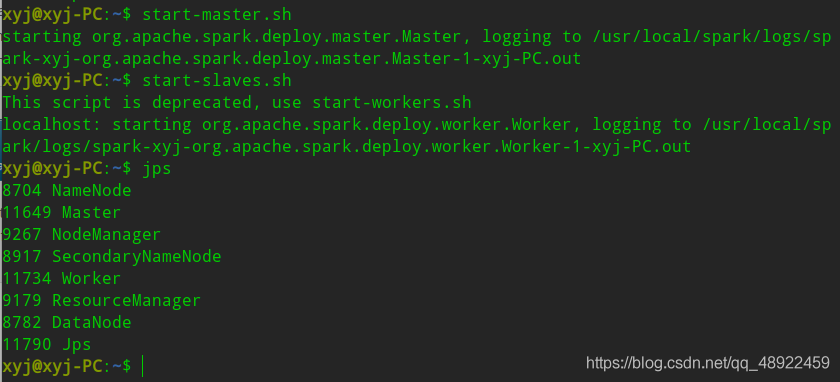
启动Spark使用start-master.sh和start-slaves.sh
然后输入jps,查看,多出了Master和Worker
4、开启Spark Shell
输入spark-shell进入shell:quit
结语
4.10:好了这篇文章到这就暂时结束了,Linux真sd,这系非人类,虽然早就配好了,但是等我心情好了再写吧
后续会写一个WordCount实例的教程
WordCount实例教程已写完,项目打包成jar包,可以在hadoop下运行
传送门:MapReduce基础编程,实现WordCount实例
















 wechat
wechat alipay
alipay